Parquet at HuggingFace
Work
This work was realized for Hugging Face .
In 2022, we decided to push the adoption of the Parquet format for datasets, as it’s generally adapted to machine learning data. In that sense, we decided to automatically convert every dataset to Parquet. The converted files are available in a special “branch” of the dataset repository. Read the docs for more information.
In 2024, I developed a Parquet metadata viewer for Hugging Face, allowing users to easily inspect the metadata of their Parquet files. The component is based on the GGUF viewer for ML model metadata.
The viewer is a Svelte component which uses hyparquet to parse the Parquet files.

In 2025, I did experiments to display the content difference between two Parquet files. Parquet is a columnar format, and each column is stored in pages within “row groups”. By comparing the size of these pages, we can detect (with some margin of uncertainty) which pages are different between two files. Check the tool in the Parquet diff notebook.
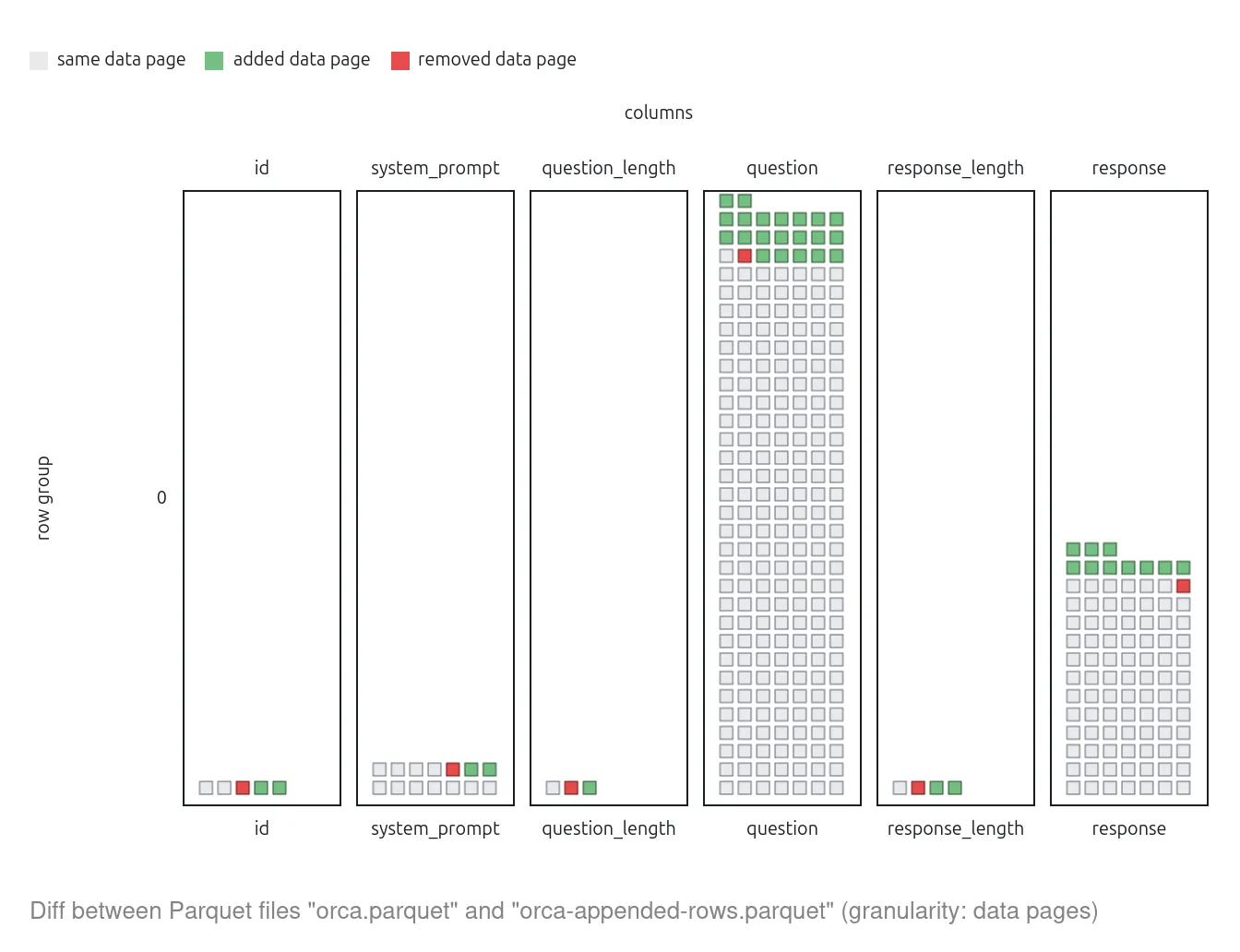
We also used visual tools to represent how parameters like compression or CDC (chunk-based compression) used when writing Parquet files can impact the difference between to files after an operation (read Parquet Content-Defined Chunking for more details).
